随着机器学习越来越多地进入社会的每一个角落,相应的训练任务也成为了云端数据中心最关键的运算负载之一,同时这也推动了半导体相关芯片市场的蓬勃发展。在云端训练芯片领域,虽然一直有不同的挑战者,但是Nvidia一直保持着龙头的位置。从2012年深度学习复兴,依靠Nvidia GPU的CUDA生态成功克服训练效率难题并成功掀起这一代人工智能潮流之后,Nvidia的GPU一直是训练市场的首选芯片。
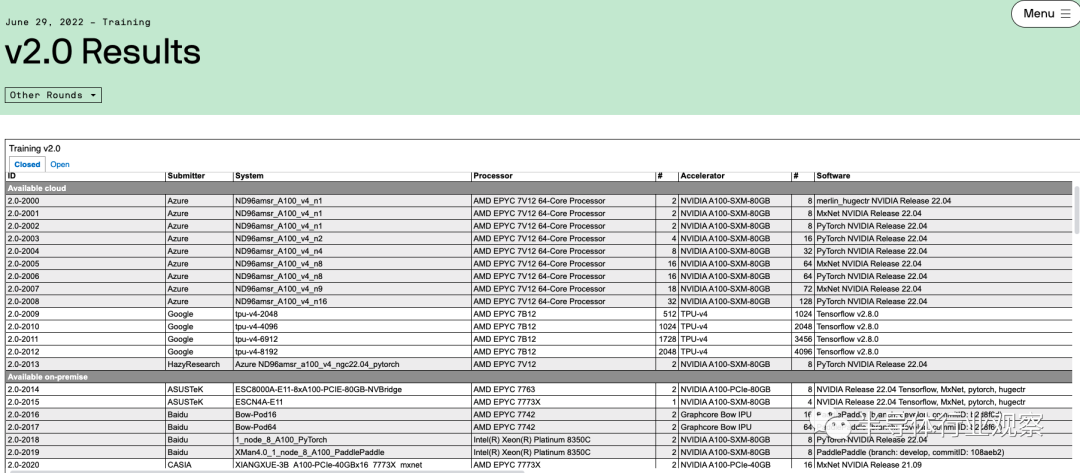
上周MLperf公布的最新训练榜单也再次印证了Nvidia的稳固地位。MLPerf是由机器学习业界的行业组织ML Commons牵头做的标准榜单,其中训练榜单的具体测评方法是ML Commons提供一些业界最流行的机器学习模型的训练任务,而不同的机构会自行去使用不同的处理器和AI加速芯片配合相应的软件框架去搭建系统执行这些训练任务,并且将结果提交到MLPerf来汇总和公布。每过一段时间,该榜单都会更新一次以包括新的芯片以及新的训练任务。在最新的6月29日公布的MLPerf训练2.0版本的结果中,Nvidia的领先地位可以从榜单中的两个地方看出:
首先是使用Nvidia GPU提交结果的数量。在这次MLPerf的最新训练榜单中,绝大多数(90%以上)机构提交的训练结果都是基于Nvidia的GPU做训练加速,而如果再仔细看结果,会发现Nvidia的GPU是和不同的机器学习训练框架兼容性最好的。例如,Google、Intel和GraphCore都上传了使用非Nvidia GPU的结果(Google使用TPU v4,Intel使用Habana Gaudi芯片,而Graphcore使用Bow IPU),但是这些竞争芯片对于深度学习框架支持的广度都不及Nvidia——基本上所有深度学习框架都会支持Nvidia的GPU,但是支持其他芯片的深度学习框架种类则有限。这也从一个角度说明了Nvidia在生态上的领先。